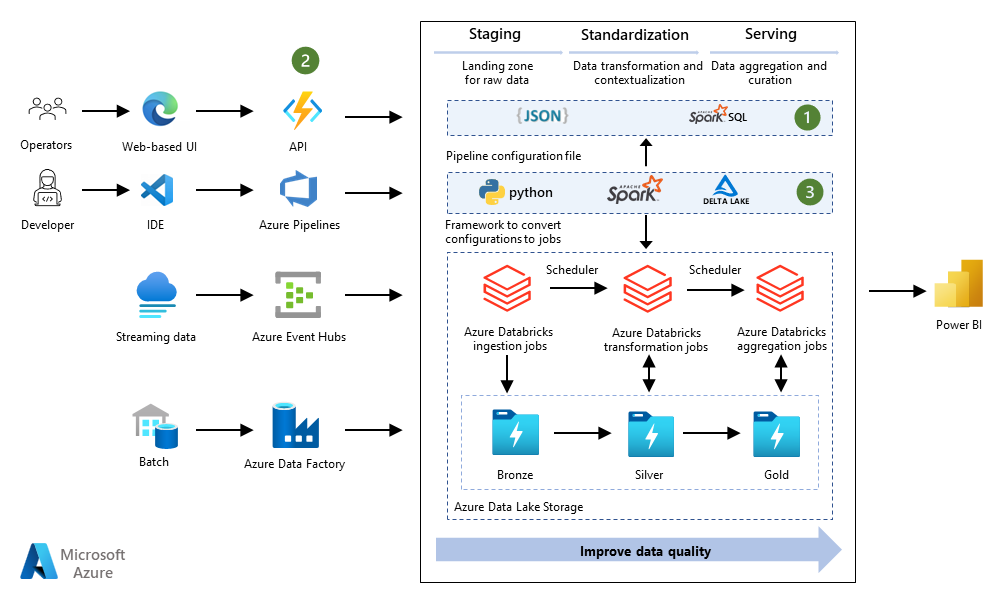
Explore the world of cloud service data pipelines, where data management meets efficiency and scalability. Dive into the key components, benefits, and best practices of Cloud service data pipelines to harness the power of data for informed decision-making. Whether you are a data engineer or a business professional, understanding the intricacies of Cloud service data pipelines is crucial for optimizing data processing and analytics capabilities. Start your journey towards streamlined data workflows and improved data quality today.

Unveiling the Power of Cloud Service Data Pipelines
Embracing Efficiency and Scalability
Cloud service data pipelines revolutionize data management by streamlining processes, enhancing scalability, and boosting efficiency. Comprised of interconnected stages, from data ingestion to processing and storage, they ensure seamless data flow.
Key Concepts and Terminology
Terms like ETL (Extract, Transform, Load), data lakes, and micro-batching are fundamental in cloud data pipelines. Understanding these concepts is vital for creating efficient data workflows in the cloud environment.
Cloud Computing in Data Management
Cloud computing underpins modern data management, offering flexible storage, processing power, and advanced analytics tools. Its scalability and accessibility make it the backbone of agile data operations.
Benefits of Cloud Data Pipelines
Leveraging cloud services for data pipelines unlocks benefits like cost-effectiveness, rapid deployment, automated scaling, and enhanced security. Cloud platforms enable speedy development, seamless integration, and real-time analytics, driving informed decision-making.

Designing and Implementing a Data Pipeline in the Cloud
Step-by-Step Guide:
To build a cloud service data pipeline successfully, start by analyzing your data sources, defining data processing steps, selecting appropriate cloud services, and designing a scalable architecture. Implement automation for seamless data flow and ensure robust monitoring for performance evaluation.
Best Practices for Data Handling:
Incorporate efficient data ingestion methods to collect data from diverse sources, utilize data transformation techniques for cleansing and structuring, and leverage secure cloud storage for safe data retention. Implement data versioning and quality checks to maintain data integrity throughout the pipeline.
Overcoming Challenges:
Address challenges like data latency, security concerns, and data processing bottlenecks by implementing data partitioning, encryption mechanisms, and optimizing data processing algorithms. Use parallel processing and caching mechanisms to enhance data pipeline performance and ensure smooth data flow.
Optimizing Performance:
Enhance cloud data pipeline performance by scaling resources dynamically, implementing data parallelization techniques, and optimizing data processing workflows. Utilize monitoring tools for real-time performance insights, conduct regular performance tuning, and consider automation for managing resources efficiently.

Mastering Data Integration and Interoperability
Techniques for integrating data from multiple sources into a cloud service data pipeline
Integrating data from diverse sources entails employing ETL (Extract, Transform, Load) processes or ELT (Extract, Load, Transform) strategies within cloud service data pipelines. Utilizing connectors, APIs, and data ingestion tools aids in seamless data integration, ensuring a streamlined flow of information for analysis and decision-making.
Ensuring data consistency and quality throughout the cloud service data pipeline
Maintaining data consistency involves thorough data validation, cleansing, and enrichment procedures at each stage of the cloud service data pipeline. Implementing data quality checks, deduplication methods, and error handling mechanisms sustains the integrity and reliability of data, facilitating accurate insights and analytics.
Strategies for handling data formats, schemas, and transformations within cloud service data pipelines
Effective handling of data formats, schemas, and transformations necessitates understanding the data model requirements and utilizing appropriate transformation techniques like mapping, filtering, and aggregation. Employing schema-on-read or schema-on-write approaches based on the use case optimizes data processing efficiency and enhances compatibility within the cloud service data pipeline ecosystem.
Best practices for data governance and security in cloud service data pipelines
To uphold data governance and security in cloud service data pipelines, implementing role-based access controls, encryption mechanisms, and audit trails is essential. Regular monitoring, compliance adherence, and data privacy regulations enforcement safeguard data assets, mitigate risks, and ensure confidentiality and integrity throughout the data processing lifecycle.

Data Analytics and Machine Learning
Leveraging Cloud Data Pipelines for Data Analytics and Machine Learning Applications
Cloud service data pipelines revolutionize data analytics and machine learning by providing scalable infrastructure for processing vast datasets. Harnessing the power of cloud service data pipelines enables real-time analysis, predictive modeling, and insights-driven decision-making, empowering businesses to stay competitive in the data-driven era.
Techniques for Data Exploration, Feature Engineering, and Model Training
Data analysts utilize cloud service data pipelines to explore data, engineer features, and train machine learning models efficiently. Leveraging cloud resources, analysts can perform in-depth data exploration, extract valuable insights through feature engineering, and optimize model training processes, leading to more accurate predictive models and informed decisions.
Considerations for Deploying and Managing Machine Learning Models in the Cloud
When deploying machine learning models in the cloud, considerations like scalability, reliability, and security play a crucial role. Cloud service data pipelines offer a robust infrastructure for deploying and managing machine learning models seamlessly, ensuring reliable performance, scalability for varying workloads, and maintaining data security standards.
Best Practices for Data-Driven Decision-Making and Optimization
Incorporating best practices in utilizing cloud service data pipelines enhances data-driven decision-making and optimization processes. By ensuring data quality, establishing data governance frameworks, and implementing performance monitoring mechanisms, organizations can extract maximum value from their data analytics and machine learning endeavors, driving informed decisions and continuous optimization.

The Evolving Landscape of Cloud Service Data Pipelines
Latest Trends and Innovations
In the realm of cloud service data pipelines, the latest trends revolve around automation, AI-driven analytics, and real-time processing. Automated pipeline monitoring and optimization, coupled with the integration of machine learning algorithms for predictive insights, are paving the way for more efficient data processing and decision-making.
Future Directions and Advancements
The future of cloud service data pipelines is shifting towards serverless computing, enabling seamless scalability and cost-efficiency. Advancements in cloud-native technologies, like Kubernetes, are streamlining deployment processes, while data encryption and privacy measures are becoming paramount to ensure compliance and data security.
Emerging Use Cases and Applications
Emerging applications of cloud data pipelines span various industries, from healthcare to finance, leveraging data for personalized healthcare solutions, fraud detection, and customer behavior analysis. Real-time data processing and edge computing are becoming essential for IoT devices, enabling rapid data insights and responses.
Predictions and Expert Insights
Experts predict a surge in hybrid cloud strategies, where organizations blend on-premises and cloud data pipelines for enhanced flexibility. The future holds a focus on data governance, ensuring data quality and regulatory compliance. Moreover, the integration of advanced analytics and AI will drive innovation, shaping the future of cloud service data pipelines.